
- Inscription
- Connexion
- A propos de l'Osint
Dans cet article, nous allons définir l'expression OSINT, puis, dans un second temps, nous aborderons la notion de cycle du renseignement.
Enfin, nous aborderons la question de la légalité des recherches et de leur utilisation.
L’expression OSINT, Open Source INtelligence, peut être traduite en français par Renseignement d’Origine Source Ouverte (on dit aussi ROSO, pour les fans d’acronymes).
Dans cette expression, il y a deux notions importantes : celle de renseignement, et celle de source ouverte.
La donnée en soi n’a que peu de valeur. Il peut s’agir d’un évènement, d’une photo, d’un article, d’un port ou d’un tweet, d’une mesure physique à un instant précis, …
Isolée de son contexte, une donnée n’a pas forcément de signification. C’est parce que l’on va recouper plusieurs données que l’on va pouvoir construire une information qui va avoir du sens.
Prenons un exemple, volontairement en dehors de toute contexte de renseignement ou d’investigation. Un état de stock de marchandises à un instant T, la température dans une cuve, …, sont autant de données brutes qu’il va falloir valoriser. Celles-ci peuvent être remises en perspective, par exemple en observant leur évolution dans le temps. Cela devient une information qui a du sens.
On peut aller plus loin en comparant cette évolution à une autre période : la période immédiatement précédente ou alors la même période, mais l’année précédente. On peut aussi chercher une corrélation avec un évènement extérieur.
Reprenons notre exemple de température. Supposons que nous pouvons monitorer la température de cinq cuves. Celle-ci doit rester aux alentours de 20°C. Nous constatons que la température d’une cuve sort de la fourchette autorisée : c’est une donnée. L’évolution dans le temps nous montre une évolution lente et régulière : cela devient une information. En parallèle, nous constatons que les températures mesurées des quatre autres cuves restent, quant à elles, stables : c’est une autre information. Enfin, après quelques recherches, nous allons peut-être découvrir qu’un facteur extérieur influence la température de notre cuve. Cette nouvelle information, associée aux autres précédemment découvertes, nous permet d’obtenir un renseignement nous permettant une prise de décision.
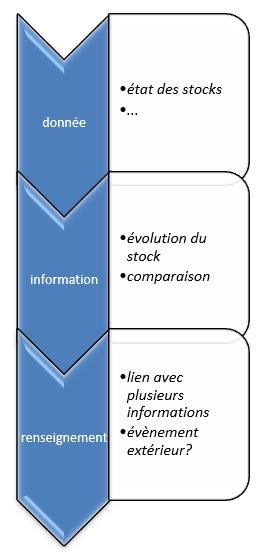
Ce qu’il faut retenir, c’est qu’une donnée isolée n’a d’intérêt que si l’on réalise un travail de regroupement, d’intégration et d’interprétation. Ce travail mené sur plusieurs données peut nous amener à une ou plusieurs informations, puis à un renseignement.
L’OSINT, c’est la même chose. A partir d’une image, on pourra peut être trouver une date, un lieu, un pseudo, etc …
" OK, mais ces données, elles doivent être fiables ? "
C’est mieux, oui ! Les données doivent être validées, leur source doit être légitime et vérifiée. Mais ce n’est pas toujours possible, donc il faudra penser à faire des recoupements.
" Et, ces données, on les trouve où ? "
En source ouverte, pardi !
Pour faire simple, une donnée en source ouverte, c’est tout ce qui est public, ou accessible à tout un chacun, … et, bien sûr, de façon légale (ça parait évident, mais cela ne fait pas de mal de le rappeler).
Il n’est donc pas question d’accéder à des données classifiées ou secrètes.
Une donnée en source ouverte ne signifie pas qu’elle est forcément gratuite ou entièrement accessible depuis Internet.
Dans certains cas, il peut être nécessaire d’acheter un article de presse (média payant), ou un Kbis auprès du greffe du tribunal de commerce.
Dans d’autres cas, une démarche formelle auprès d’une administration est peut-être nécessaire.
Bref, il est nécessaire d’identifier les sources de données possibles et de savoir comment collecter les données utiles.
L’OSINT est donc une technique qui vise à collecter des données en source ouverte, à valoriser ces données, à les intégrer, pour produire du renseignement utilisable.
La notion “intelligence” étant assez large, on a identifié des sous-familles spécialisées. Dans la famille INT, donnez moi …
Pour certaines de ces familles, le renseignement peut être obtenu à partir de sources ouvertes, mais pas toujours. C’est le cas, par exemple, du GEOINT : certaines images sont publiques (open source), d’autres non. Le GEOINT fait donc partiellement partie de l’OSINT …
Et enfin, l’OSINT inclut d’autres sources … qui ne se terminent pas forcément par un INT ! C’est le cas de recherche cadastrales. Ce n’est pas parce qu’il n’y a pas d’acronyme que ce n’est pas de l’OSINT.
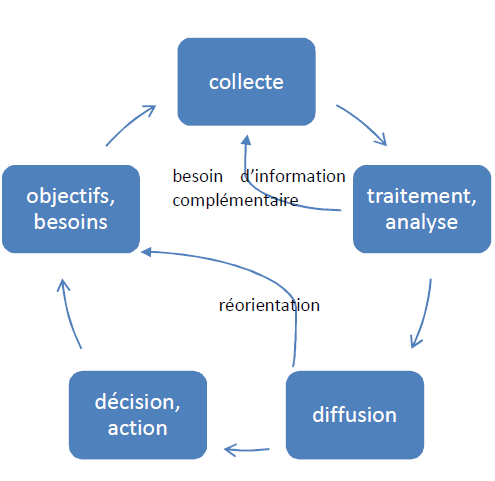
On formalise généralement les étapes successives de la recherche d’informations par un cycle composé de quatre phases successives : l’identification des besoins, la collecte, l’analyse, la diffusion. On y ajoute parfois, selon certains auteurs, une cinquième phase : la phase de décision.
La première étape consiste à traduire les problématiques et les enjeux en axes de veille ou de recherche. La question qui se pose est d’identifier les informations utiles.
En effet, il n’y a aucun intérêt à collecter des masses d’information qui traitent de thèmes généraux ou qui n'apportent rien de déterminant.
Il va donc falloir identifier les questions auxquelles on va tâcher de répondre. Une question assez large peut se décliner en questions davantage ciblées. D’ailleurs, au fur et à mesure, les questions peuvent évoluer.
Cette seconde phase doit débuter par déterminer le périmètre des sources. On va identifier les sources fiables et pertinentes.
Par exemple, pour une image, les métadonnées (EXIF) doivent faire systématiquement partie du périmètre d'étude.
Pour une adresse mail, le nom d’utilisateur et le nom de domaine sont des points d’entrée qui font partie du périmètre d’étude.
Mais comment je fais pour déterminer le périmètre ?
Pas de panique, on verra tout ça plus en détail dans la partie "méthodologie" ☺️
A ce stade, on n’en est pas encore à l’analyse. Il vaut mieux collecter “large”. De plus, les données peuvent parfois être volatiles : il est donc largement préférable de collecter et d’enregistrer immédiatement les données obtenues.
La question des pivots, ou des rebonds, est importante. Par exemple, une photo de profil amène à un pseudo. Il est important de documenter les pivots, car il y a un risque que l’on ne se souvienne plus de la raison qui nous a amené à pivoter.
" Euhhh, c’est possible d’oublier un truc pareil ? "
Et oui, c’est possible, selon la masse de données collectées.
Cette phase de traitement / analyse / exploitation doit transformer la donnée en information.
Il faut donc remettre les données en perspective, les interpréter et les analyser. Cela peut être une étape fastidieuse.
On a trouvé un compte sur un réseau social. C’est bien, mais de ce compte, il va falloir extraire les posts ou les données pertinentes.
C’est aussi lors de cette phase que l’on va éliminer les (parfois nombreux) faux-positifs.
A ce stade, commencer une chronologie peut être pertinent, dans certains cas.
L’analyse peut aussi déboucher sur un besoin complémentaire d’informations : on bascule à nouveau sur la phase de collecte.
On peut regrouper ces deux étapes.
La diffusion doit évidemment être adaptée au rôle de chacun et doit normalement déboucher sur une décision … qui peut être une réorientation des besoins. Cette situation va se traduire par de nouvelles recherches.
On redémarre alors un nouveau cycle.
De façon générale, consulter une donnée en source ouverte est légal dans la mesure où cette donnée est publique.
Attention toutefois, il peut arriver que l’on soit amené à trouver des documents qui n’avaient pas vocation à être public. On verra ce point notamment dans l'article sur les moteurs de recherche.
Même si la recherche en elle-même ne pose pas de difficultés en soi, le fait de télécharger un fichier clairement privé de cette manière pourrait être interprété par la justice comme une action illégale.
Allons plus loin : le fait de diffuser des informations manifestement privées est une action parfaitement illégale.
Enfin, rappelons que le doxing, pratique qui consiste à diffuser publiquement des informations personnelles (même si ces informations ont été obtenues légalement) est illégal.
L’article 223-1-1 du code pénal dispose en effet que la divulgation de données personnelles d’une personne, d’informations relatives à sa vie privée, familiale ou professionnelle, ou bien permettant de la localiser, est punie par la loi. La peine encourue est de trois ans d’emprisonnement et de 45 000 € d’amendes. Cette peine est aggravée lorsque la personne est dépositaire de l’autorité publique, journaliste, mineur ou vulnérable.
" Ca rigole pas, là ! "
Non ! Il faut rester vigilant et avoir conscience que la recherche, la collecte, la diffusion, sont des notions bien différentes …